Data is not a scarce resource. In order for it to be useful and become information and knowledge we need to unearth the gems buried under gigabytes of waste and connect them in a mosaic, something that we can use and share. We have decided to focus on data that matters. Nowadays many datasets are released by scientific institutions, governmental organizations and communities under an open data license. Those datasets can help to address the challenges we have in front of us, improve our work and products, and help us to plan our future the way we want.
Areas of Expertise
We work on projects in the areas described in the following sections

Earth Observation
Climate change is already having an impact on our lives and it is something we will have to deal with for many decades to come. We have seen how data and information are important to address a pandemic. We will need much more to mitigate the consequences of the climate change, to adapt to it and make our social and physical infrastructures resilient. Satellites play a fundamental role in monitoring the essential climate variables that can allow citizens and political leaders to make the appropriate decisions to avoid the worst-case scenarios. We have already been working with the Copernicus services, the Sentinel-1 and Sentinel-2 satellite data. The open data policy under which the Copernicus data is released allows many more actors to participate in raising awareness and in enabling communities to adapt to a changing environment.
Data Science and Machine Learning
Nowadays software engineers have to process data that does not come just as tables. Text and images are much more common input data than structured data. Classical algorithms are still useful but we need the machines to learn from the data. This requirement is not at all new since scientists and engineers are used to analyze data using statistics to build a model of the system they are dealing with. Machine learning, and in particular Deep Learning, allows us to perform tasks such as image segmentation, object detection or text translation, that were simply impossible just 10 years ago. We have successfully implemented an application for land use and land cover classification using a Deep Learning architecture and we are ready to apply the technology in many other tasks in computer vision and digital image processing.
Big Data
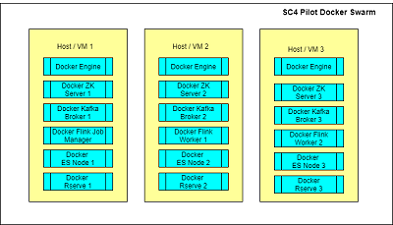
In real world applications we usually need different frameworks for messaging, indexing, processing and storage. We also need our systems to operate in high availability with low latency and to be able to scale to handle an increase in the number of requests or in the amount of data. These requirements can be fulfilled by using a more powerful machine up to a certain point. Most of the time applications are deployed in a cloud environment where standard machines are made available to the application so that the requests can be distributed to different servers. In such environment the system components are partitioned, replicated and distributed to the machines. Furthermore nowadays these components are deployed as docker containers onto virtual machines. We have deployed distributed systems in production environments on AWS and on-premises to address the needs of companies and public administrations.
Knowledge Graphs and Linked Data
Google added a knowledge graph infobox to its search results in 2012. Since then users have been able to access content not just by keywords but following meaningful links between different types of resources. That was the first realization of the Semantic Web idea: using terms from a shared vocabulary to power intelligent applications and to “unleash a revolution of new possibilities”. We have been working on knowledge graphs since they were only an academic field of study. We believe that we are still just at the beginning and that many more actors can benefit from the Linked Data principles and technologies.
Software Engineering
Software development involves people. As obvious as such statement may appear it is just a reminder that software development is a challenging endeavor that can succeed only when a team follows a development process and has access to a version control system, an issue tracker, a documentation system and writes tests before implementing the solution. An issue tracker allows the team to measure its performance and to address any problem that may arise before it is too late. We have been involved in many projects with partners from all over the world. We share the best practices, tools and processes to fulfill our projects’ requirements and achieve our clients goals. We use docker containers to build applications on top of microservices that can be easily deployed on a cloud environment or on-premises.

Information Security
Security is a major concern. We have created resources about cryptography and Public key Infrastructure to help citizens in using open source tools to keep their data private.